Model providers advertise context windows in tokens. The number on the spec sheet is how much input the model accepts, not how much of it the model reliably uses. I've seen this distinction cause real production problems for teams building document Q&A systems, code search tools, and multi-document analysis pipelines.
Short answer: LLMs don't attend equally to all positions in their context. Performance is strongest at the beginning and end, weakest in the middle, and degrades further as total context length grows. The 1M token spec number is an input ceiling, not a performance guarantee. For most production retrieval tasks, RAG outperforms long context because it gives the model fewer tokens with higher signal density.
Why the middle of your context gets ignored
The mechanism is causal masking. During a transformer's forward pass, each token attends to all tokens before it in the sequence. A token at position 1 accumulates attention from every subsequent token through the full model depth. A token at position 500,000 only matters to positions 500,001 onward. Tokens at the start of the context receive proportionally more attention weight than tokens in the middle, and this is not a bug — it is how transformers work.
Researchers at Stanford, Berkeley, and Samaya AI measured this directly in 2023. Their paper Lost in the Middle: How Language Models Use Long Contexts varied the position of relevant documents within a fixed-length context and measured retrieval accuracy. Performance dropped by up to 40% for content placed in the middle, and the pattern held across model sizes and families.
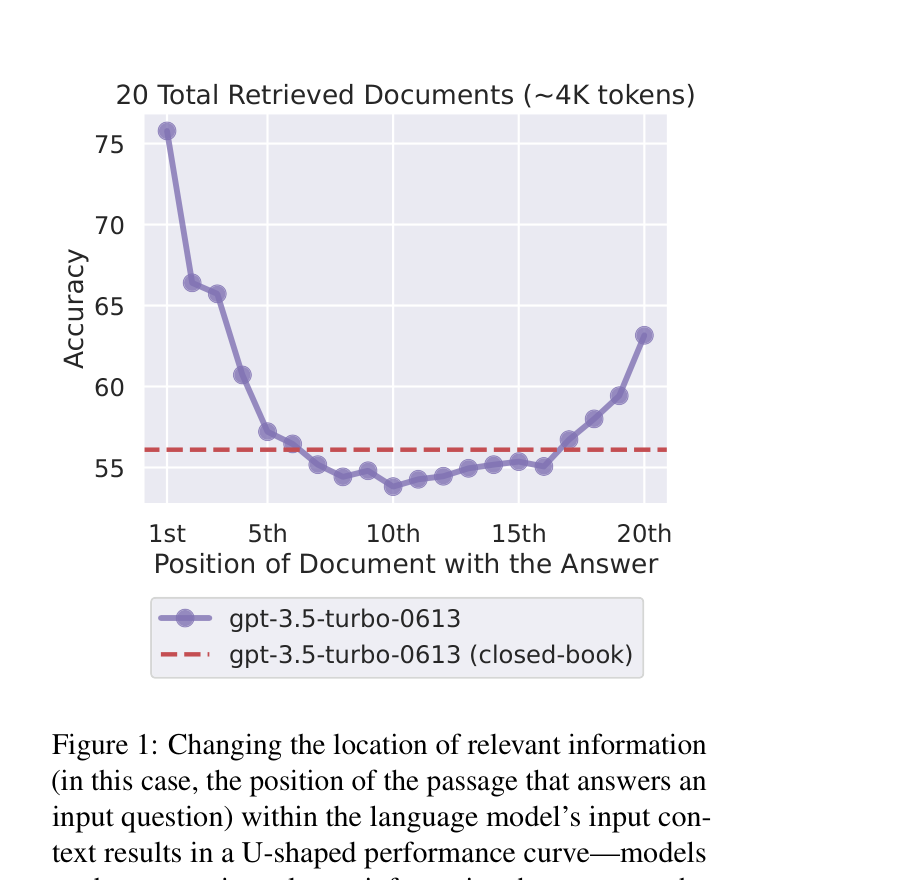
Flash attention does not change this. Flash attention tiles the attention computation to fit in fast SRAM, which cuts memory use and speeds up processing considerably. The attention weights that create positional bias are unchanged. You get the same biased distribution, faster.
Context rot: the volume problem on top of the position problem
Positional degradation and context rot are separate issues. Positional degradation is about where content sits. Context rot is about how much total content you have.
A 2025 paper studying context length in isolation found that retrieval accuracy degrades as total context grows, even when relevant documents are placed correctly. Adding more irrelevant tokens makes it harder for the model to isolate the signal, regardless of placement. The Understanding AI writeup on context rot describes this as a noise problem: every additional irrelevant token competes with the content you care about. At 500k tokens, there is a lot of competition.
My read on the context window arms race: providers have gotten very good at answering "can we technically accept this many tokens." The harder question — does the model reason well across all of them — remains largely unanswered. Every major provider has shipped million-token windows. The underlying attention architecture that creates positional bias has not changed.
What long context actually costs
Attention complexity is O(n²) in the naive implementation. Double the context length, quadruple the compute. Flash attention reduces this in practice, but a 200k token prompt still costs substantially more than a 5k prompt, on every request.
The first thing you feel is latency. Time to first token scales with context length, which I covered in more depth in my post on TTFT. A model that starts generating its first response token 8 seconds after receiving a 200k token prompt is working correctly. For interactive applications, 8 seconds is not acceptable.
The second thing is the bill. Most providers price input tokens similarly to output tokens. Loading 500,000 tokens per request means paying for 500,000 tokens per request. I have watched teams "simplify" their retrieval pipelines by dumping everything into context, not realizing they were trading a few days of engineering work for a 10x increase in ongoing API costs.
Long context vs RAG vs hybrid: when each approach wins
| Approach | Use when | Breaks when | Cost profile |
|---|---|---|---|
| Long context | Task requires reasoning across document relationships — legal analysis, full codebase understanding, synthesizing a research paper | Relevant content lands in middle; total context volume is large | High — O(n²) per request |
| RAG | Fact retrieval from a knowledge base; answering specific questions about documents | Task requires understanding how parts of documents relate to each other | Low to medium — retrieval is cheap, you control token count |
| Hybrid | High-value queries needing both retrieval precision and relationship reasoning | Engineering complexity is a real cost to factor in | Medium to high |
The tradeoffs between RAG and other approaches are worth thinking through carefully before committing to an architecture. RAG's main advantage over long-context approaches is not cost alone — it is signal density. You pass the model fewer tokens with a higher ratio of relevant content, and models reliably perform better on that.
Long context genuinely wins for tasks where chunking destroys what you are trying to understand: how decisions in one part of a codebase affect another, how arguments in a contract interact across sections, how findings in a paper build on each other. For "answer questions about our knowledge base," RAG almost always wins.
What works in production
Put relevant content at the top of the context. The positional bias is real and consistent, and working with it beats pretending it does not exist.
Run evals with test questions where the answers are in the middle of the context. Model providers do not design their long-context benchmarks that way, which is why benchmark numbers look better than production results. A rough heuristic: for a 128k context model, the reliable zones are roughly the first 25k and last 25k tokens. The middle 75k is where you are taking on risk.
If you are building systems that genuinely need long context, Together AI's writeup on long-context fine-tuning is worth reading before you finalize your architecture. Introl's guide on long-context infrastructure goes into evaluation methodology in detail.
Explaining infrastructure tradeoffs like these clearly for developer audiences is a big part of what I do when writing for AI companies. My work page has examples if that is relevant.
Questions
What context length is actually usable in practice?
For most models, the first 20-30% and last 20-30% of the advertised context are the reliable zones. For a 128k model, that is roughly 25k tokens at each end. The middle is where retrieval accuracy degrades meaningfully. Run evals on your own data rather than trusting provider benchmarks.
Does putting relevant content at the start always help?
Yes, consistently. It is the cheapest single intervention for improving long-context retrieval quality. It feels wrong because humans read front-to-back with roughly equal attention, but transformers do not work that way.
When is long context the right answer over RAG?
When the task requires reasoning over relationships between documents rather than retrieving specific facts. When chunking would destroy the thing you are trying to understand. For knowledge base Q&A, use RAG.
Does flash attention fix positional bias?
No. Flash attention changes how the attention computation runs, not what the attention weights are. The same positional bias exists, computed faster.
If the model accepts 1M tokens, why not just use it?
Put your test questions where the answers are in the middle of the context and measure accuracy. If you are getting correct answers, use it. If you are getting confident-sounding wrong answers, you have found your practical limit, and it is almost certainly much less than 1M tokens.