A lot of the advice around coding LLMs still sounds like it came from the Codex era, when one benchmark jump could actually tell you something useful. That is not really where the market is anymore.
Kimi K2.5 scores 99.0 on HumanEval. That looks great. It does not tell you whether you should trust the model inside a real codebase.
The short answer: stop looking for one winner. The useful question is not "what is the best coding LLM?" The useful question is "best for what?" If I were picking today, I would start with Claude for agentic coding, Gemini 3.1 Pro for reasoning-heavy work, DeepSeek V3.2 for cost-sensitive production, GPT-5.3-Codex for OpenAI-native workflows, and Qwen3-Coder for self-hosted setups.
| Use case | Model I would start with | Why |
|---|---|---|
| Agentic coding | Claude Opus 4.6 | Best track record for multi-step code editing |
| Algorithmic and reasoning-heavy work | Gemini 3.1 Pro | Strong reasoning and long-context performance |
| Cost-sensitive production | DeepSeek V3.2 | Best economics without falling off a cliff |
| OpenAI-native workflows | GPT-5.3-Codex | Purpose-built OpenAI coding line |
| Self-hosted coding | Qwen3-Coder | Best current open model to evaluate first |
Why HumanEval is the wrong metric to use
HumanEval was useful when coding models were much weaker. It is not very useful now.
Runloop's analysis makes the core issue clear. HumanEval checks whether a model can complete short, isolated functions in a controlled format. Real software work is not that.
The bigger problem is contamination. The paper "The SWE-Bench Illusion" argues that strong benchmark performance is often partly recall, not reasoning. OpenAI also stopped self-reporting SWE-bench Verified scores for frontier models after contamination concerns were raised. That should tell you how careful you need to be.
Here is the practical takeaway:
- HumanEval can still tell you if a model is obviously weak
- It cannot tell you how a model behaves in a real codebase
- A model that aces a benchmark can still be painful to use in production
SWE-bench Verified: the better signal, with caveats
SWE-bench Verified is currently the closest thing to a meaningful coding benchmark. It evaluates models on real GitHub issues, actual pull requests, actual test suites, and multi-file changes. The official SWE-bench leaderboard is the best place to track current scores.
As of March 2026, the official Verified leaderboard shows a tight cluster rather than a clean winner:
- Claude 4.5 Opus: 76.8%
- Gemini 3 Flash: 75.8%
- MiniMax M2.5: 75.8%
- Claude Opus 4.6: 75.6%
- GPT-5.2-Codex: 72.8%
- GLM-5: 72.0%
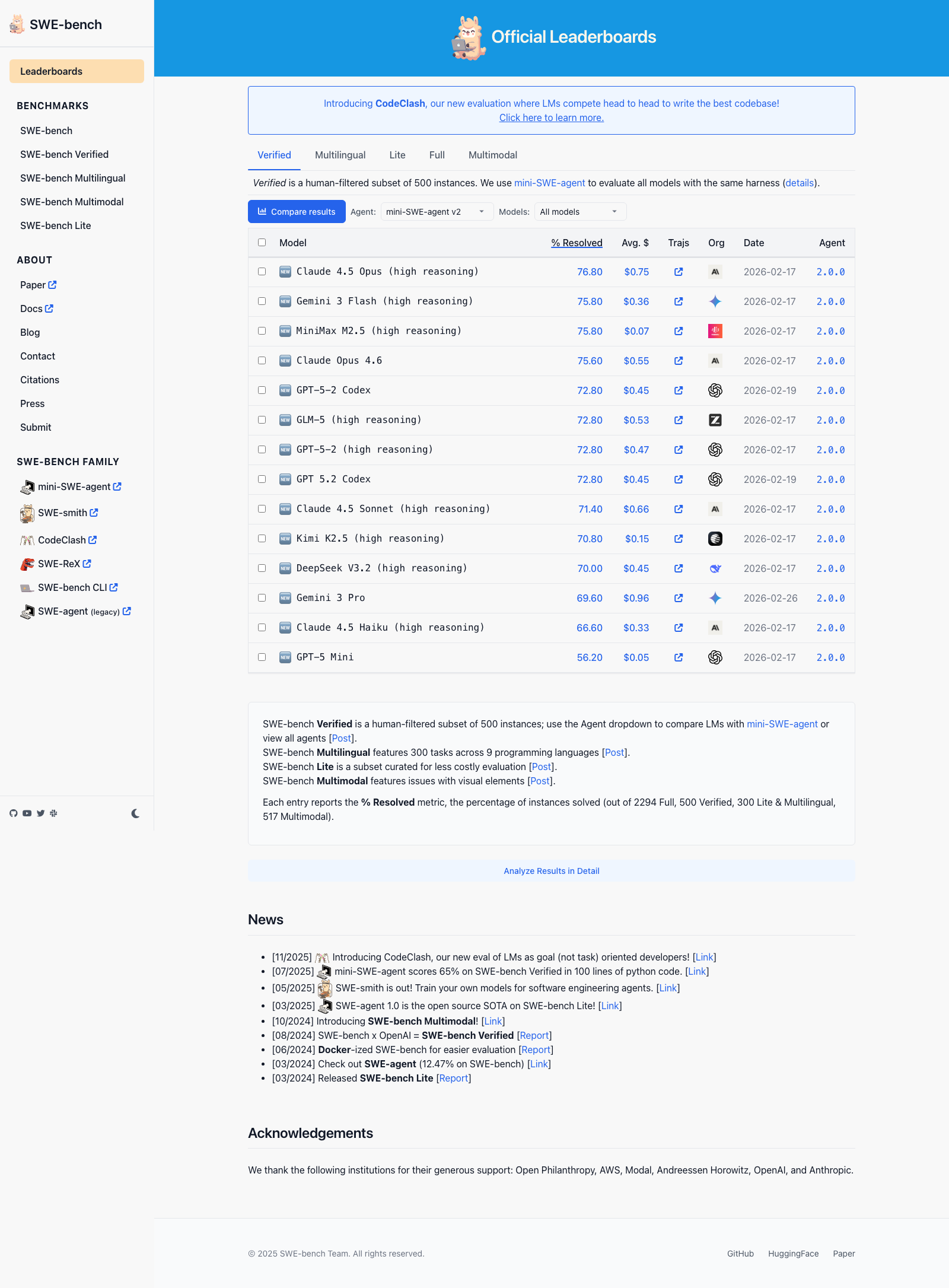
One thing worth stating explicitly: benchmark boards and model release names do not move in lockstep. Google's current flagship reasoning and coding model is Gemini 3.1 Pro, even though public leaderboards may still show older Gemini 3 variants in the table. This is exactly why I do not trust articles that treat one benchmark screenshot like final truth.
For teams doing rigorous evaluation, SWE-bench Pro is worth watching. It uses 1,865 tasks across 41 actively maintained repositories in Python, Go, TypeScript, and JavaScript. Scores drop substantially relative to Verified. In my view, the gap between a model's SWE-bench Verified number and its SWE-bench Pro number is a better indicator of real generalization than either score alone. Epoch AI's benchmark tracker keeps a maintained history of verified results if you want to track how specific models have moved over time.
For agentic and autonomous coding: Claude Opus 4.6
If you are building an AI agent that writes, edits, and reviews code with minimal human intervention, Claude is still where I would start. The benchmark score matters, but what matters more is that teams building serious coding products keep landing there in production. Replit noted a 0% error rate on their internal code editing benchmark with Claude, compared to 9% with the prior version. That kind of internal measurement means more to me than another polished benchmark chart.

Claude also handles long-context reasoning better than most alternatives. Running a 200,000-token context window across an entire codebase and then making targeted, coherent edits is not a benchmark trick. It is a real capability that matters for agent workflows. I covered the infrastructure layer around this kind of reasoning in my earlier piece on agent harnesses. The model is only one part of what makes an agent reliable. The execution loop, state manager, and context assembly matter just as much.
The honest limitation: Claude Opus 4.6 is expensive. For high-volume coding tasks or teams doing continuous code review at scale, the cost-to-performance ratio pushes you toward Sonnet 4.5, which sits at 77.2% on SWE-bench and is meaningfully cheaper per million tokens.
For competitive programming and algorithmic work: Gemini 3.1 Pro
If your team writes algorithms, does quantitative research, or works on problems where mathematical reasoning is central to code correctness, Gemini 3.1 Pro is where I would start.
Google is not positioning Gemini 3.1 Pro as a minor point release. This is the Gemini model they are putting forward for harder reasoning and more complex problem-solving. That is also where it makes the most sense for coding: algorithm design, deep code understanding, and tasks where you want the model to think first and code second.
The long context window is also genuinely useful for processing large codebases. I have seen teams at data infrastructure companies use Gemini specifically for this by loading an entire repository into context before asking the model to trace a bug. It works better than most people expect, though context length and context utilization are not the same thing, and every long-context model gets sloppier as you push it toward the ceiling.
For cost-sensitive production use: DeepSeek V3.2
DeepSeek V3 changed the economics of coding LLMs when it was released. The technical report describes a 671B parameter mixture-of-experts architecture that achieves frontier-competitive performance at open-weight costs. V3.2-Exp's SWE-bench score is lower than Claude Opus, but the cost differential is not marginal. It is an order of magnitude.
For production pipelines that generate code completions, run code review, or assist with documentation at scale, DeepSeek V3.2 is not just a backup option. For some teams, it is the rational choice. I have seen DevTools teams use it for internal tooling where the cost of Claude at full volume would have been hard to justify. The quality gap is real. For narrow and repeated tasks, the economics can still win.
The open-weight availability matters too. Running DeepSeek on your own infrastructure eliminates API dependency, gives you data control, and changes the economics again. DeepSeek Coder is the purpose-built variant worth evaluating for pure coding tasks if you want to run it locally.
For OpenAI-first agent workflows: GPT-5.3-Codex
If your team is already standardized on the OpenAI stack, the model to pay attention to is GPT-5.3-Codex. I do not mean a vague idea of "GPT-5 for coding," and I do not mean the unofficial "GPT-5.4 Codex" name floating around on social posts. OpenAI's official coding releases right now are GPT-5.3-Codex and the faster GPT-5.3-Codex-Spark variant.
That distinction matters. OpenAI is clearly treating coding as its own product line, not just a capability of the base chat model. The official SWE-bench board still lists GPT-5.2-Codex rather than 5.3-Codex. That is a good reminder that benchmark tables lag launches, product naming, and real production use. If I were already deep in the OpenAI ecosystem, I would test 5.3-Codex before assuming Claude or Gemini automatically wins for my workflow.
For everyday IDE autocomplete: the OpenAI/Copilot ecosystem
For developers who want fast, reliable autocomplete and code suggestions inside their editor, the practical answer is still the OpenAI-centered ecosystem. This is not about model purity. It is about product quality. GitHub Copilot, Cursor, and Windsurf all have mature integrations, predictable latency, and feature sets built around how developers actually work.
Autocomplete is a different product than an agentic coding assistant. The benchmark numbers are less relevant when the model is making 200 small suggestions per hour and the developer is accepting or rejecting each one in under a second. What matters there is latency, suggestion accuracy on short completions, and how well the model reads the surrounding file context. The Copilot/Cursor class of tooling is optimized for this in a way that frontier research models are not.
One thing worth knowing: this distinction between autocomplete performance and agentic coding performance is one of the most consistently misunderstood parts of the market. The two serve different workflows and should be judged differently. It comes up often in the technical writing briefs I get from engineering teams. My work page has examples of how I explain that kind of nuance for technical audiences.
The open-source angle
The open-weight field is finally good enough that you do not have to treat it like a compromise. If you need a self-hosted coding model, Qwen3-Coder is the first one I would test. Alibaba paired it with Qwen Code, a terminal agent built for repository-level software engineering work. That is the right frame for coding models in 2026. You are not buying weights. You are choosing a full working system.
GLM-5 is also strong enough on the public leaderboard to be worth testing. The question is not whether open models can code anymore. The question is whether your team wants to own the inference stack, serving layer, and evaluation discipline that come with running them yourself.
The caveat is that running a 70B+ parameter model in production requires infrastructure investment. You need hardware, a serving stack, and your own versioning discipline. The model weights are free; the operations are not. Teams underestimate this tradeoff consistently.
FAQ
Is Claude or GPT better for coding in 2026?
For agentic coding, including autonomous agents, multi-step code editing, and real-world bug fixing, Claude and the top Gemini/OpenAI Codex models are close enough that workflow fit matters more than headline bragging rights. For everyday autocomplete and IDE integration, Copilot and Cursor style tooling has the deeper ecosystem. Calling one "better" without specifying the task is a category error.
Are HumanEval scores still worth looking at?
Barely. At 99%, the benchmark is saturated and contamination is documented. Use it as a rough floor check, not a ranking signal. If a model scores below 80% on HumanEval in 2026, that is worth noting. Above 95%, it tells you little. SWE-bench Verified is the more honest signal for real coding work, and SWE-bench Pro is more rigorous still.
Is DeepSeek safe to use for production code?
"Safe" depends on what you mean. The model is capable. The data handling question is separate. If you use the hosted API, your code leaves your infrastructure. For sensitive codebases, run DeepSeek on your own hardware using the open weights. For internal tooling and non-sensitive projects, the hosted API is widely used by engineering teams. Know the tradeoff before you choose.
Should I use one model for everything or mix and match?
Mixing is increasingly common and often the right call. I have seen teams run Claude for agentic tasks and code review, Gemini for algorithm design and large-context work, and DeepSeek for high-volume completions where cost matters. The overhead of managing multiple API keys is low. The upside can be substantial.
What about Gemini for general coding beyond algorithms?
Gemini 3.1 Pro is competitive across most coding tasks, particularly when context window size matters. Where it falls slightly short in my experience is on sustained multi-step agentic tasks requiring coherent edits across many files over many turns. Strong model, just not where I would start for that workflow specifically.